February 8, 2018
Kaggle TensorFlow Speech Challenge
Over the holidays, I competed in the Kaggle TensorFlow Speech Recognition Challenge. The competition’s goal was to train a model to recognize ten simple spoken words using Google’s speech command data set. This is essentially the trigger word detection problem that alerts voice activated intelligent personal assistants when to pay attention.
This post briefly documents my solution written in Python and TensorFlow. As usual, the sources are available on my Github repo.
I didn’t have much experience with audio data before this competition, so I didn’t get creative with feature engineering. I initially transformed the data into spectograms but switched to Mel Frequency Cepstral Coefficients after doing some research. Rather than re-inventing the wheel, I used the Python Speech Features package to transform the data.
I usually do Kaggle competitions to learn, not necessarily to win. In this case, I tried designing my own network rather than starting with a well known architecture or published solution. Since an audio clip is a sequence of samples, my initial plan was to use a recurrent neural network or RNN. I started simple by building networks of LSTM and GRU units. That worked OK but not great.
Next, I reasoned that a pure RNN model may struggle to find common structure in words spoken at different times and frequencies. I knew that convolutional neural network layers are very successful in discovering repeated structure in images, so I thought the same may apply in this case.
I built a new model with multiple 1D convolutional layers followed by an RNN. I used a 1D convolution since the data was a 1D sequence and not a 2D image. More on that later. My hopes were that
- The 1D convolutional layers would find repeated structure over time
- The output of the 1D convolutional layers would essentially form a sequence of higher level features
- The RNN layers would learn temporal patterns in the 1D convolution feature sequences
Performance was much improved but still not as much as I liked.
At this point, I scanned the competition’s forum and found that many contestants were using 2D convolutions. This made sense, as features may shift in frequency based each speaker’s pitch.
My final model used three layers of 2D convolutions followed by a GRU RNN.
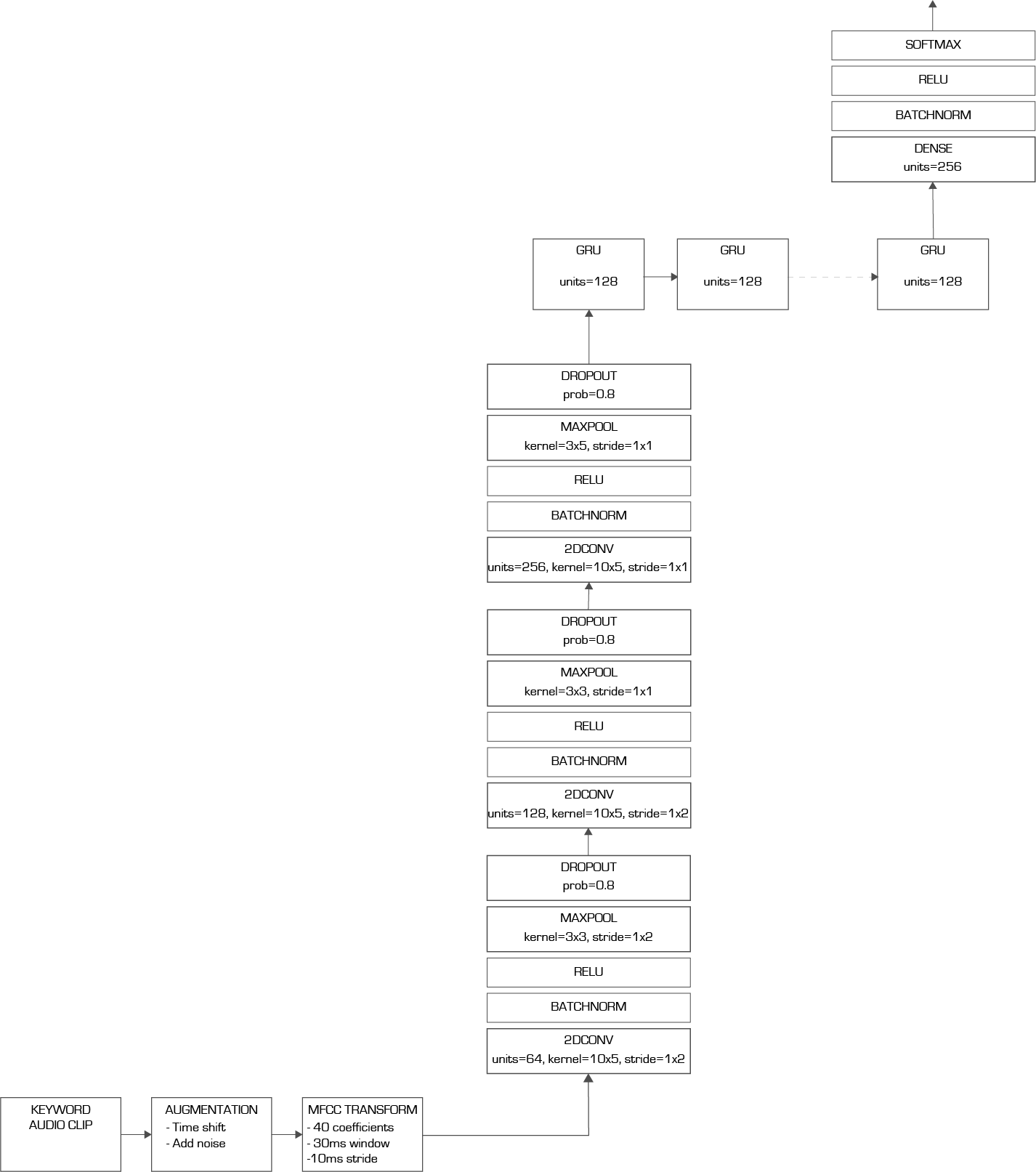
I trained the model for 30 epochs at a batch size of 512 on my NVIDIA TitanX GPU. My final score was 80.8% accuracy which placed me 479th out of 1315 teams (top 37%). Not enough to earn a bronze medal but I was still happy with my performance given that this was my first serious attempt at using RNNs.
Later, I was even happier to see that my instinct to use a 1D convolutional network followed by an RNN wasn’t that far off. The Sequence Model class in Andrew Ng’s Deep Learning Specialization on Coursera used a conceptually similar network to detect trigger words. Of course, their model was more complex but at least I was in the ball park. I just wish the Sequence Models class had been launched before the competition ended.
Tags: Kaggle , TensorFlow , DeepLearning