Using Undirected Graphs to Guide Multi-label Text Classification
The importance of multi-label classification has increased with the growth of online collaboration forums containing large amounts of text on diverse topics. User generated annotations, called tags, are commonly used to help discover relevant information. These tags are often inconsistently applied which reduces their effectiveness.
Supervised machine learning techniques can be used to identify the topics within a body of text and predict the appropriate tags. Using these techniques may substantially improve the consistency of text annotation and make finding relevant information easier. This requires machine learning algorithms capable of accurately modeling many tags and processing large data sets in reasonable amounts of time.
For my CS229 Machine Learning class project, I developed and evaluated a new Network Guided Naive Bayes (NGNB) classifier that uses undirected graphs to accurately and quickly predict labels for multi-topic text. Many multi-label prediction algorithms, in particular mixture models, explicitly consider tag co-occurrence relationships during training but not prediction. The conditional probabilities generated by these algorithms inherently confound the relationships between tags. While these techniques are effective, improved accuracy and efficiency may be obtained through explicitly considering tag relationships during prediction. NGNB explored this potential.
To evaluate NGNB, its performance and efficiency was compared to a Binary Relevance Multinomial Naive Bayes (BRNB) model and a Parametric Mixture Naive Bayes model (PMM1). All three models were implemented from scratch in the Python programming language. A data set of 200000 posts to the StackExchange website spanning 116 common tags was used to train, test, and compare the models. The data set was created from a much larger sample of posts provided by StackExchange.
The following figure shows the undirected graph formed by the co-occurrences of the 116 tags.
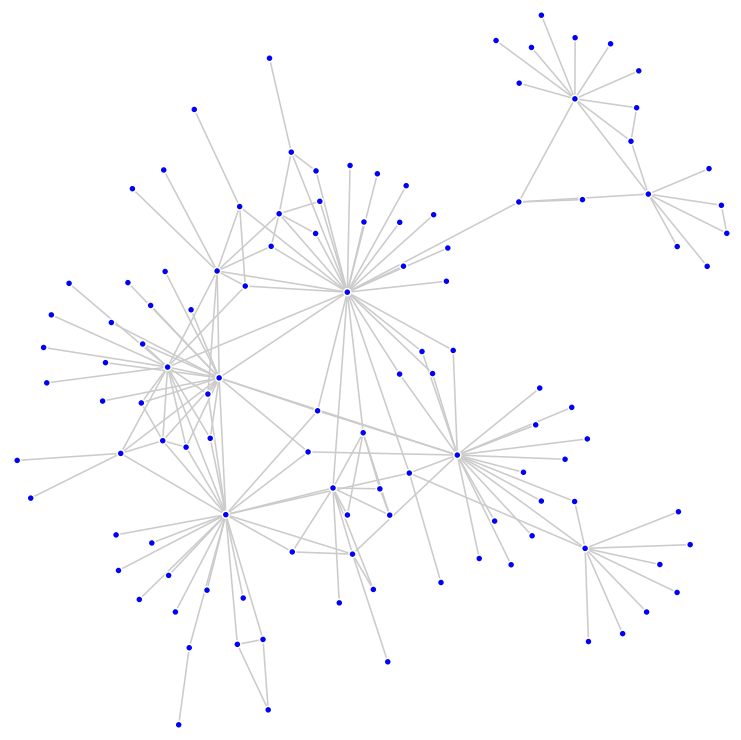
Although the network formed by this data set consisted of a single connected component, NGNB can be used with multiple component graphs.
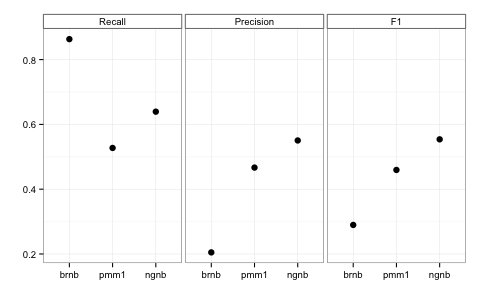
Cross validation with 10 folds showed that NGNB out-performed PMM1 on precision, recall, and F1 score while achieving training and test execution times similar to BRNB.
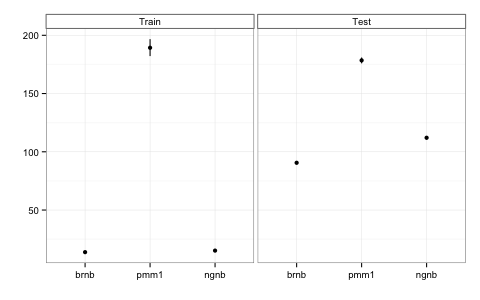
All three models suffered reduced performance and increased training time as the number of possible tags was increased. However, NGNB degraded at the smallest rate on both counts.
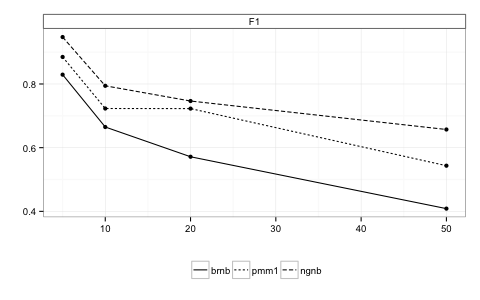
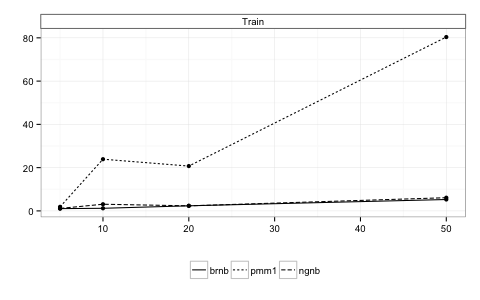
Finally, the generalization of the three models was evaluated using a test data set of 15000 additional posts not used for training or model selection. Once again, NGNB provided the best results.
| MODEL | PRECISION | RECALL | F1 |
|---|---|---|---|
| brnb | 0.207 | 0.867 | 0.291 |
| pmm1 | 0.465 | 0.524 | 0.457 |
| ngnb | 0.552 | 0.644 | 0.557 |
Overall, NGNB proved to be an interesting experiment and indicates that there is potential to the approach. See the class project paper for a more detailed discussion. The source code for all three models is available on GitHub.